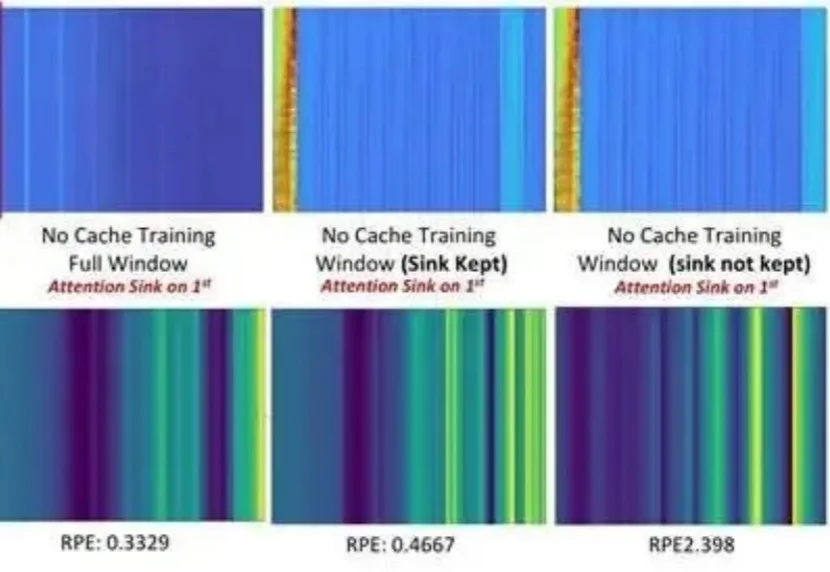
破解在线长时序重建难题!纯视觉、单卡实时的公里级流式3D重建|CVPR'26
破解在线长时序重建难题!纯视觉、单卡实时的公里级流式3D重建|CVPR'26在自动驾驶、具身智能、AR/VR应用中做3D重建,大家都想解决一个终极问题: 模型能不能像人一样,一边往前看,一边持续构建三维世界?
来自主题: AI技术研报
8250 点击 2026-03-24 16:28
 搜索
搜索
在自动驾驶、具身智能、AR/VR应用中做3D重建,大家都想解决一个终极问题: 模型能不能像人一样,一边往前看,一边持续构建三维世界?
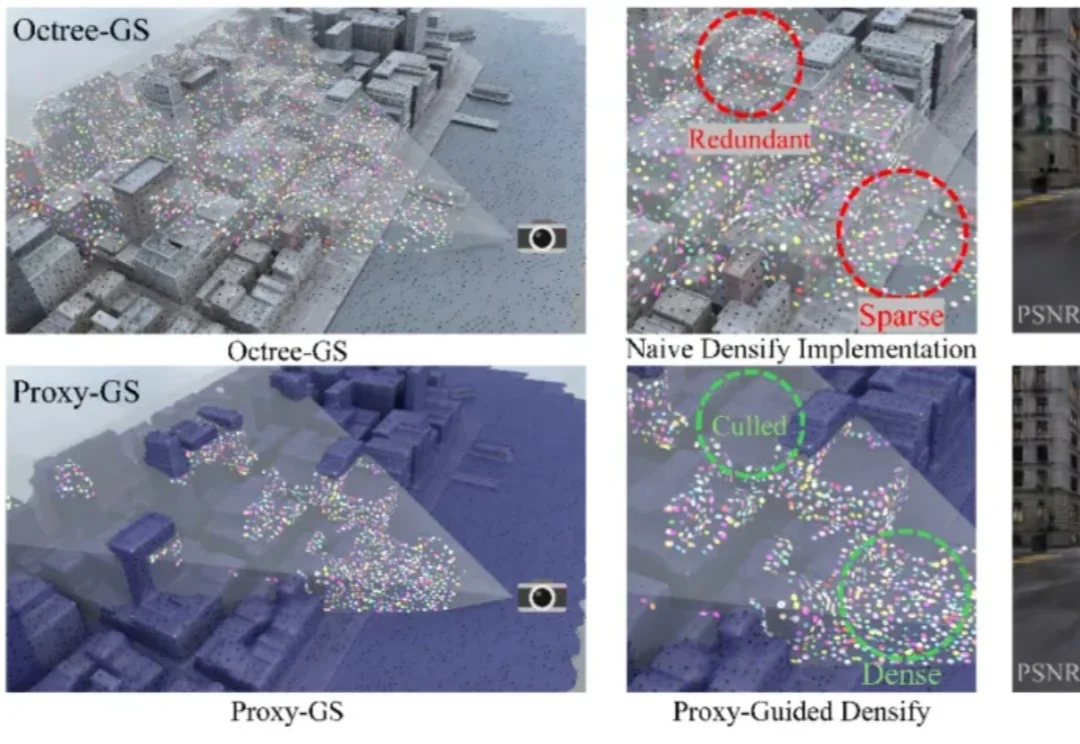
上海交通大学钟志航团队联合上海人工智能实验室、西北工业大学、四川大学等高校在 CVPR 2026 上提出Proxy-GS(Proxy-GS: Unified Occlusion Priors for Training and Inference in Structured 3D Gaussian Splatting),面向基于 MLP 的结构化 3D 高斯溅射(3DGS),

南京大学与北京大学提出MorphAny3D,无需训练即可让三维生成模型实现跨类别平滑变形。通过创新注意力机制融合源与目标特征,精准控制结构与时序,轻松完成复杂变形,效果远超传统方法。
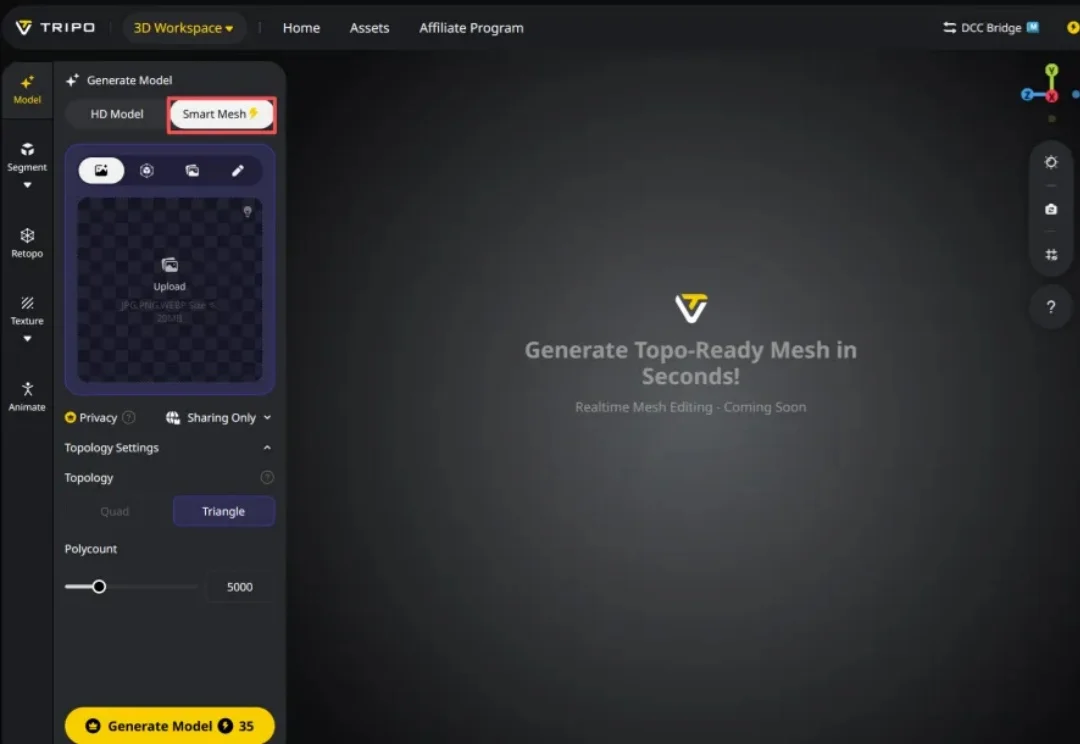
速度、质量、管线可用性,是 AI 3D 生成领域公认的不可能三角。三件事,从来没有同时成立过。直到现在。VAST 最新发布的 Tripo P1.0,首次在原生三维空间中实现概率生成,2 秒内即可输出专业建模师级别的 3D 资产,效率较现有方案提升百倍以上。
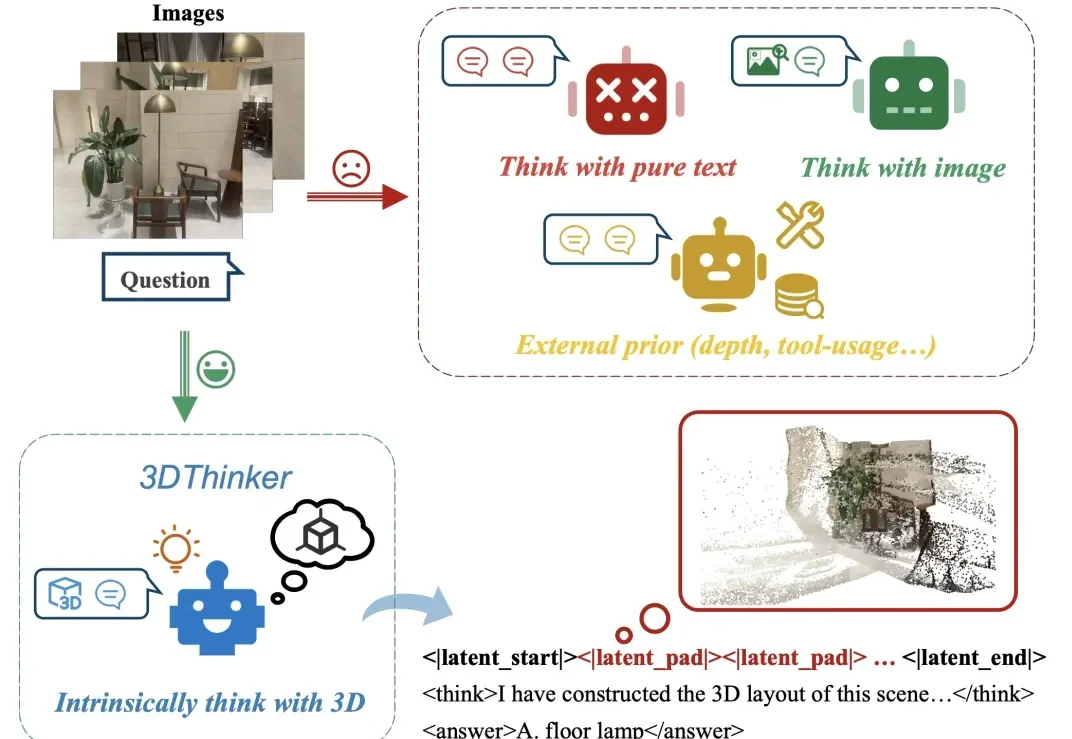
大家是否有这样的感觉?给定几张场景中拍摄的图片,往往能够在脑海中想象出这个场景的三维布局,然而当前的多模态大模型还停留于纯文本或者 2D 视觉的推理表示,限制了图像中隐含几何结构的表达能力。

据我们了解,宋亚宸创办的通用人工智能公司 VAST 近期完成了 5000 万美元 A 轮融资,领投方为阿里和上汽,元禾璞华、BV 百度风投、东方嘉富跟投,老股东春华创投和北京市人工智能产业投资基金也在继续加注。
机器之心编辑部 近日,一款名为 StoryWorld 的 iOS 产品 Demo 在海外开发者与 3D 创作者社区引发关注:用户只需用手机摄像头对准真实空间,通过语音输入描述,即可生成 3D 角色与物

通用人工智能公司 VAST 今日宣布完成 5000 万美元 A 轮融资。本轮融资由阿里、恒旭资本联合领投,元禾璞华、BV 百度风投、东方嘉富等跟投,形成覆盖顶级资本、产业巨头、知名战投的全方位赋能格局。
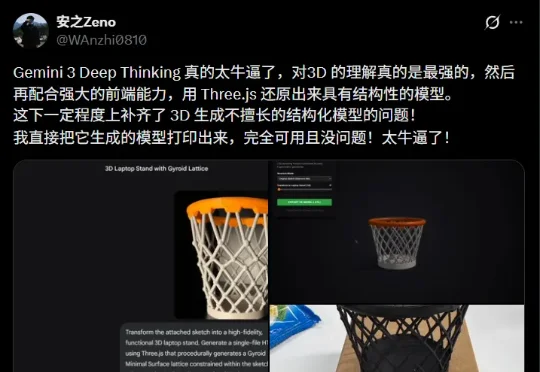
现在, Gemini 3 Deep Think 看一眼照片,就能脑补全这张锅在各个角度的长宽高、厚度甚至把手的弧度,直接变出一个立体实物原型。

英伟达新论文让AI学会先盖房、再装修。